publications
publications by categories in reversed chronological order. * denotes joint first author.
2026
- ACL ARRFrom Language Specifications to Executable Turing Machines: Evaluating LLMs as Computational Machine Designers2026ACL ARR 2026 May Submission (Under Review)
- ACL ARRCan LLMs Design Computational Machines? Pushdown Automaton Synthesis as a Test of Structured Computational Reasoning2026ACL ARR 2026 March Submission; to be committed to EMNLP 2026
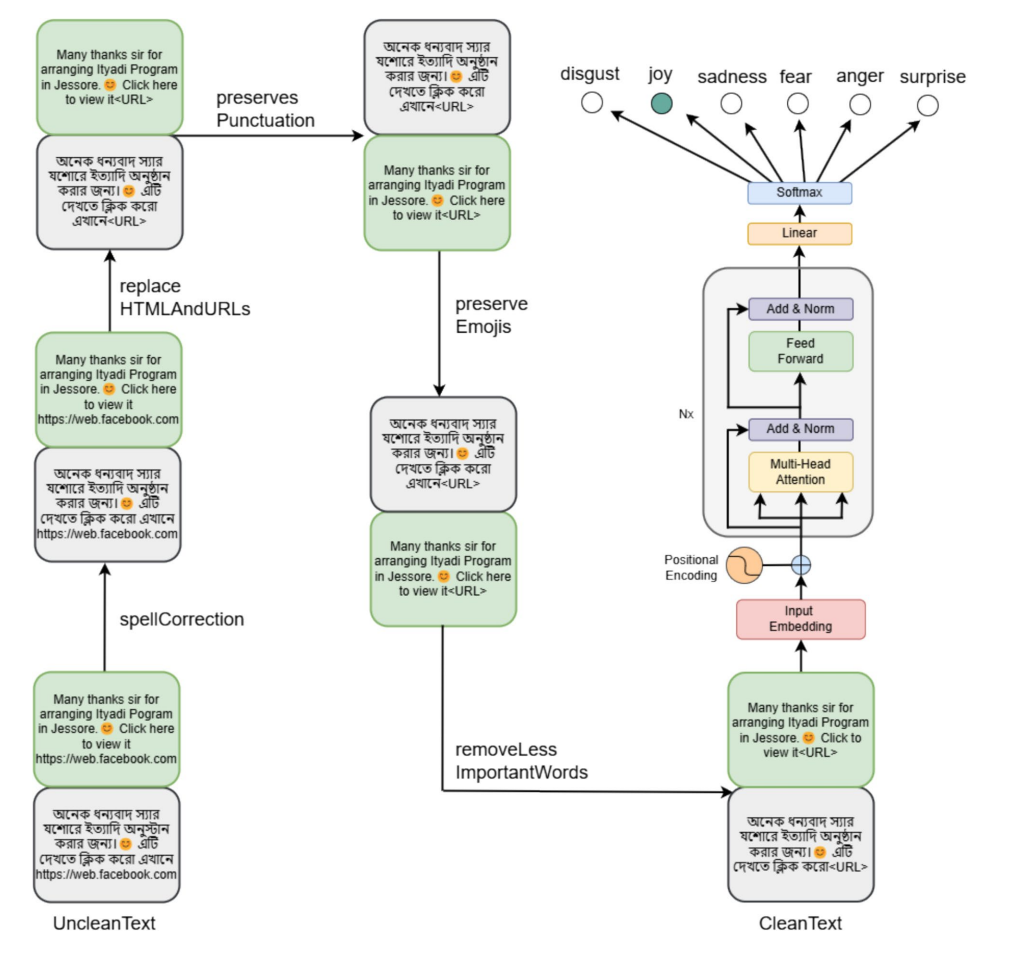
- ACL ARRCan LLMs Follow the Pulse of a Crisis? Evaluating Crisis Sentiment in Bangladesh’s July Uprising2026ACL ARR 2026 May Submission (Under Review)
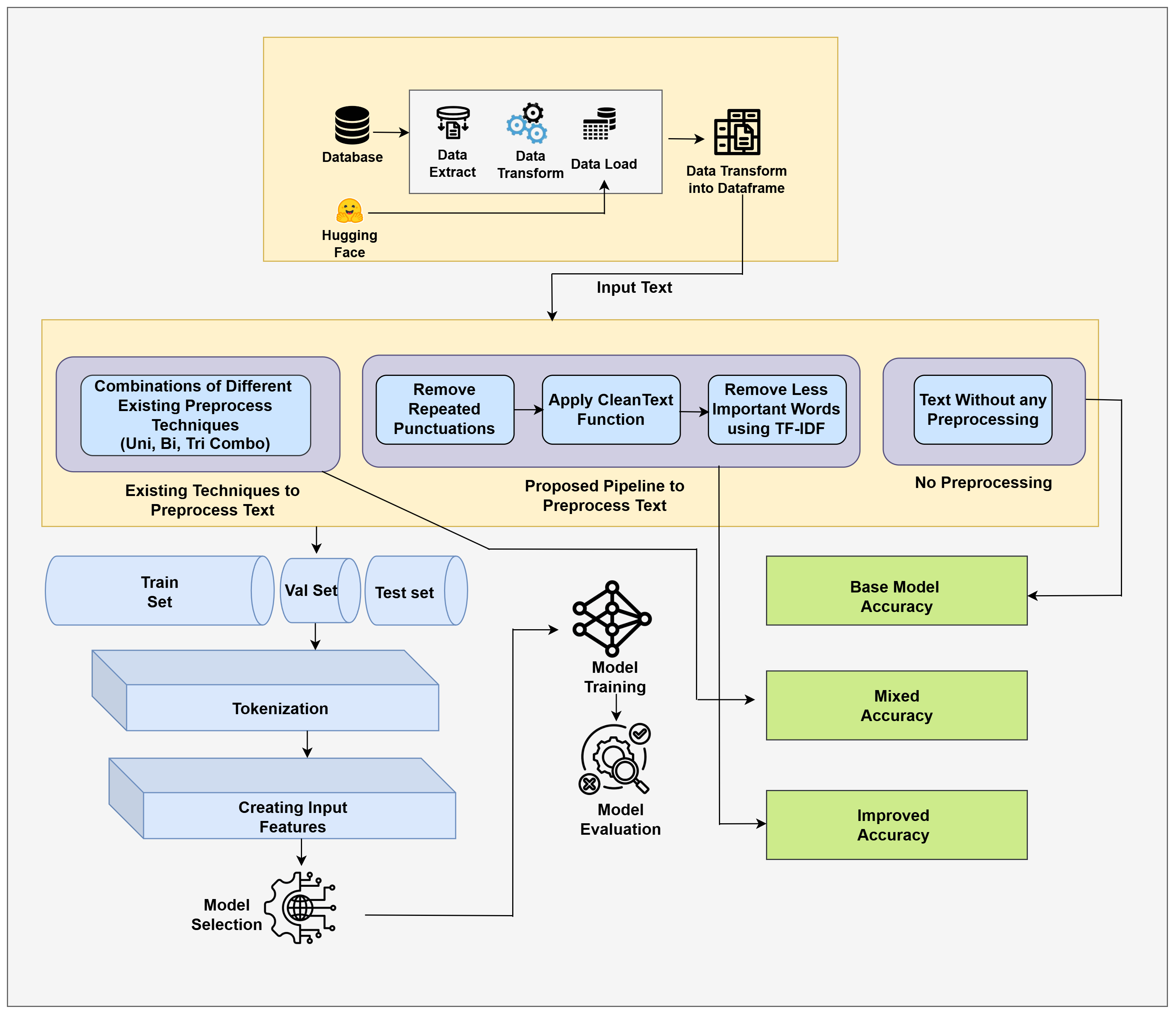
- ACL ARRBeyond Build Validity: Evaluating Behavioral Correctness in LLM-Generated Context-Free Grammars2026ACL ARR 2026 May Submission (Under Review)
- ACL ARR
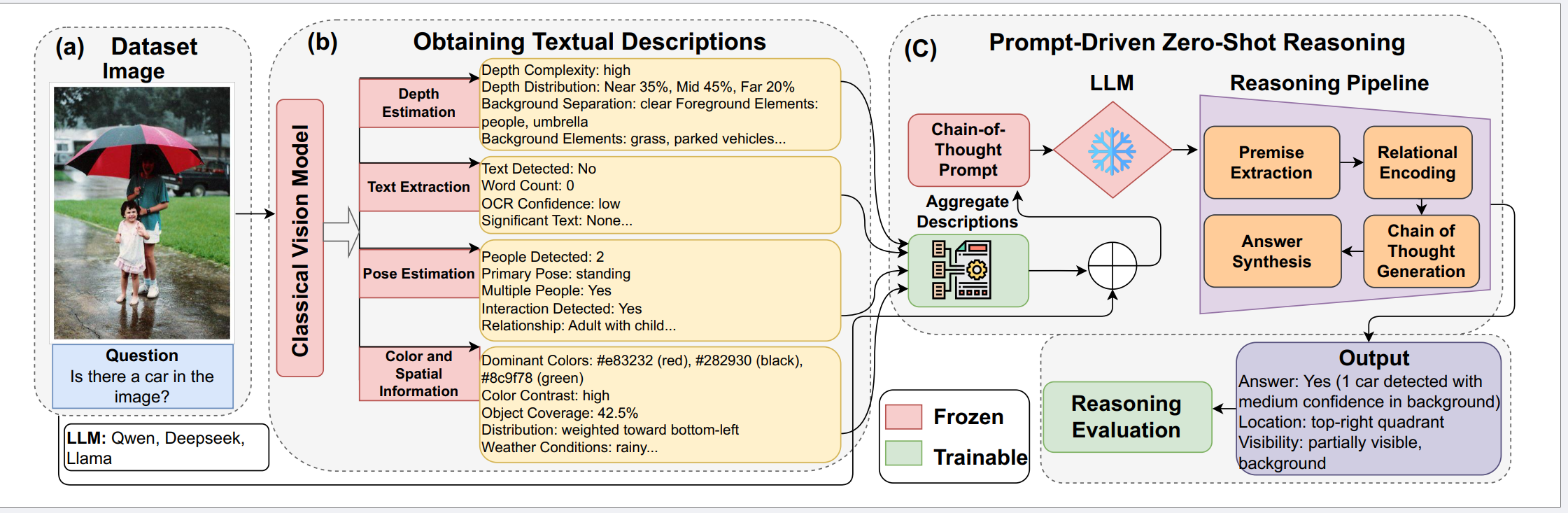
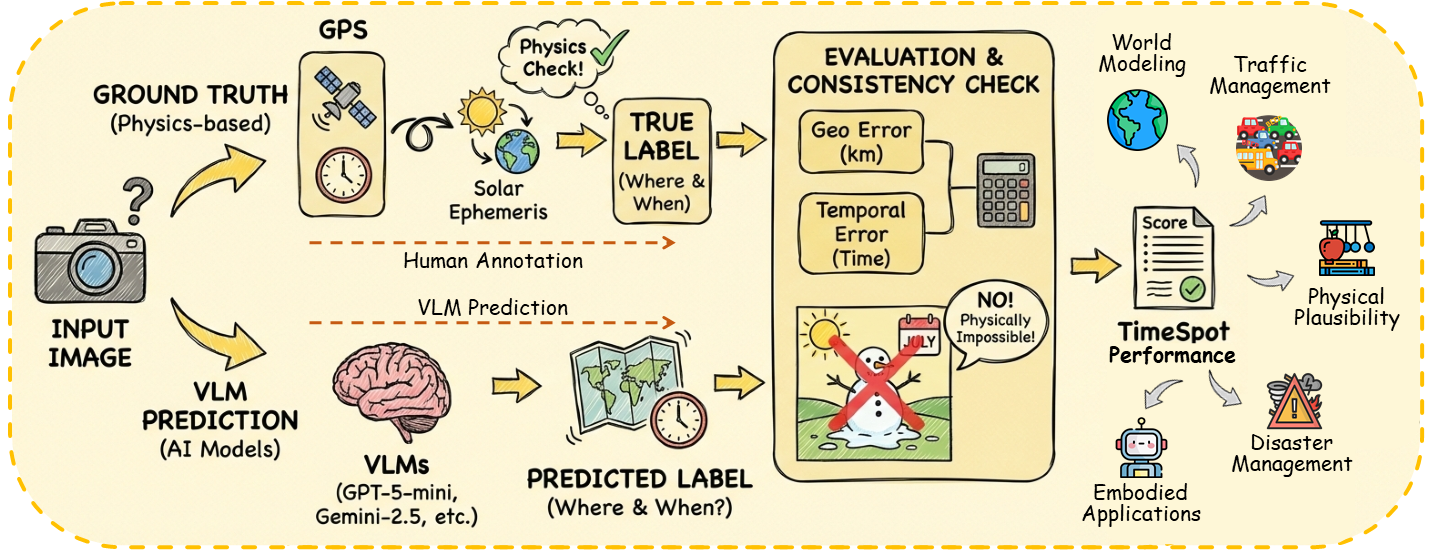
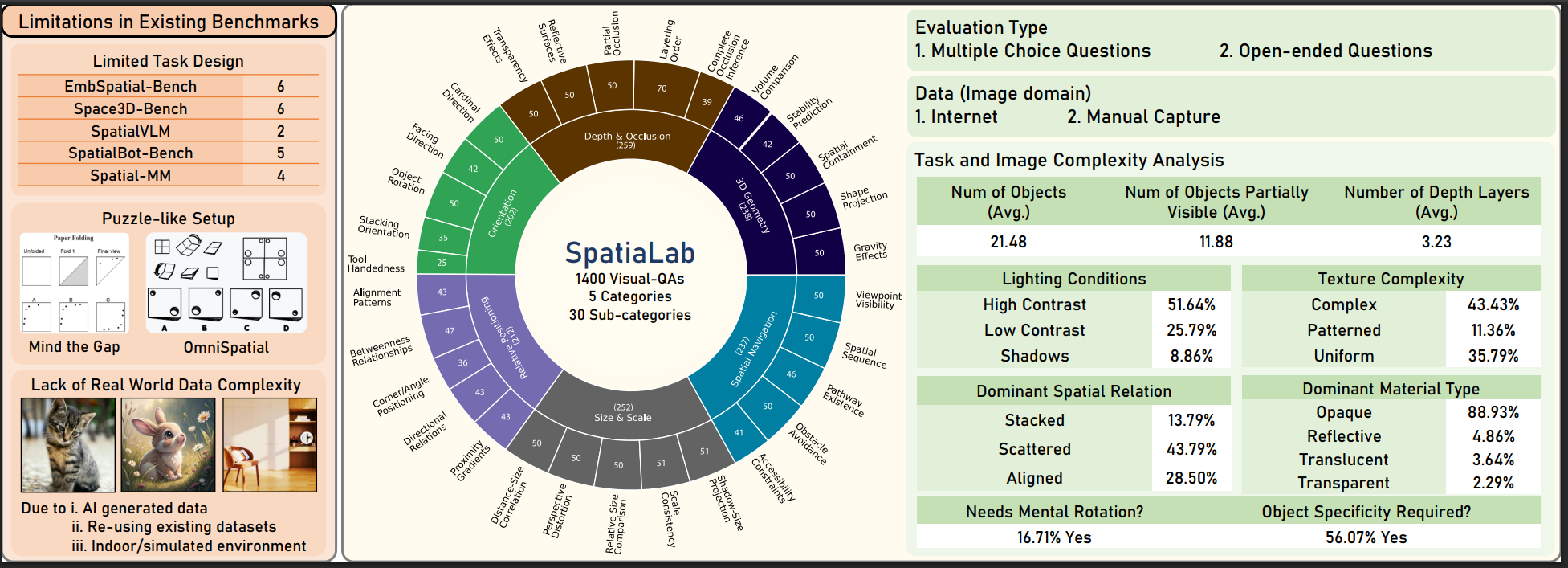
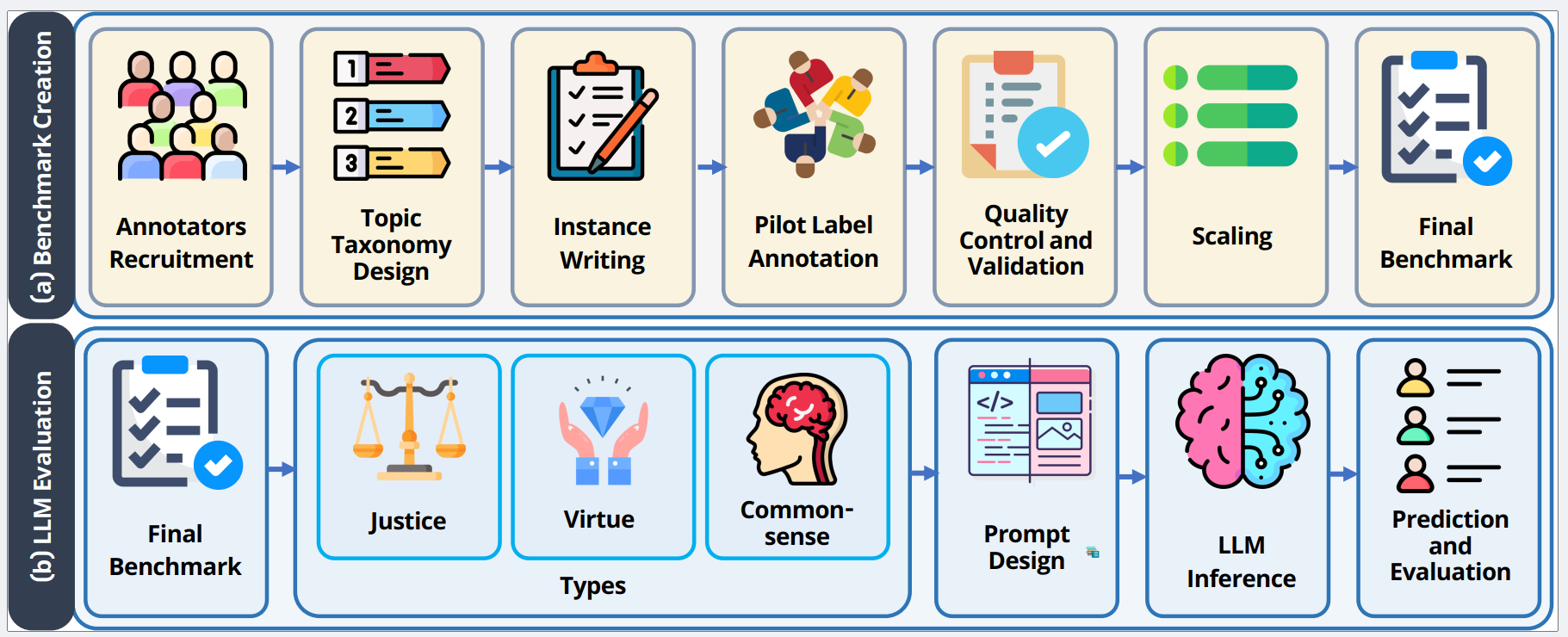
 Geo-spatial and Geo-temporal Reasoning in Vision–Language and Large Language Models: A Review2026ACL ARR 2026 March Submission (Under Review)
Geo-spatial and Geo-temporal Reasoning in Vision–Language and Large Language Models: A Review2026ACL ARR 2026 March Submission (Under Review) - NeurIPSSEISMOS: A Statistical Signal Detection Framework for Semantic Chunking2026NeurIPS 2026 Conference Submission (Under Review)
- NeurIPSInvariantBench: Can Large Language Models Exhibit Inherent Reasoning Across Equivalent Transformations?2026NeurIPS 2026 Evaluations and Datasets Track Submission (Under Review)
- ICML workshopWhen Machines Decide If a Human Wrote It: Creativity in the Age of AI DetectorsIn ICML 2026 Workshop on Human-AI Co-Creativity, 2026Workshop paper
2025
- Array
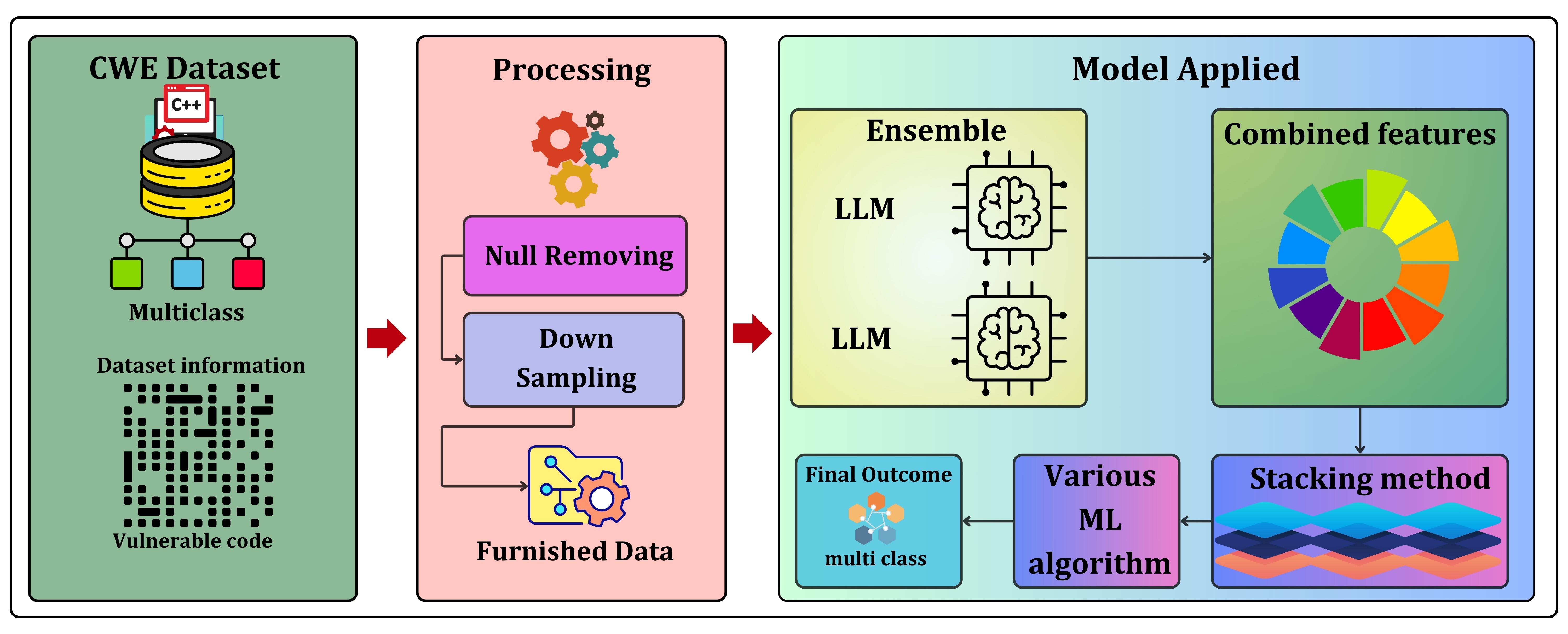
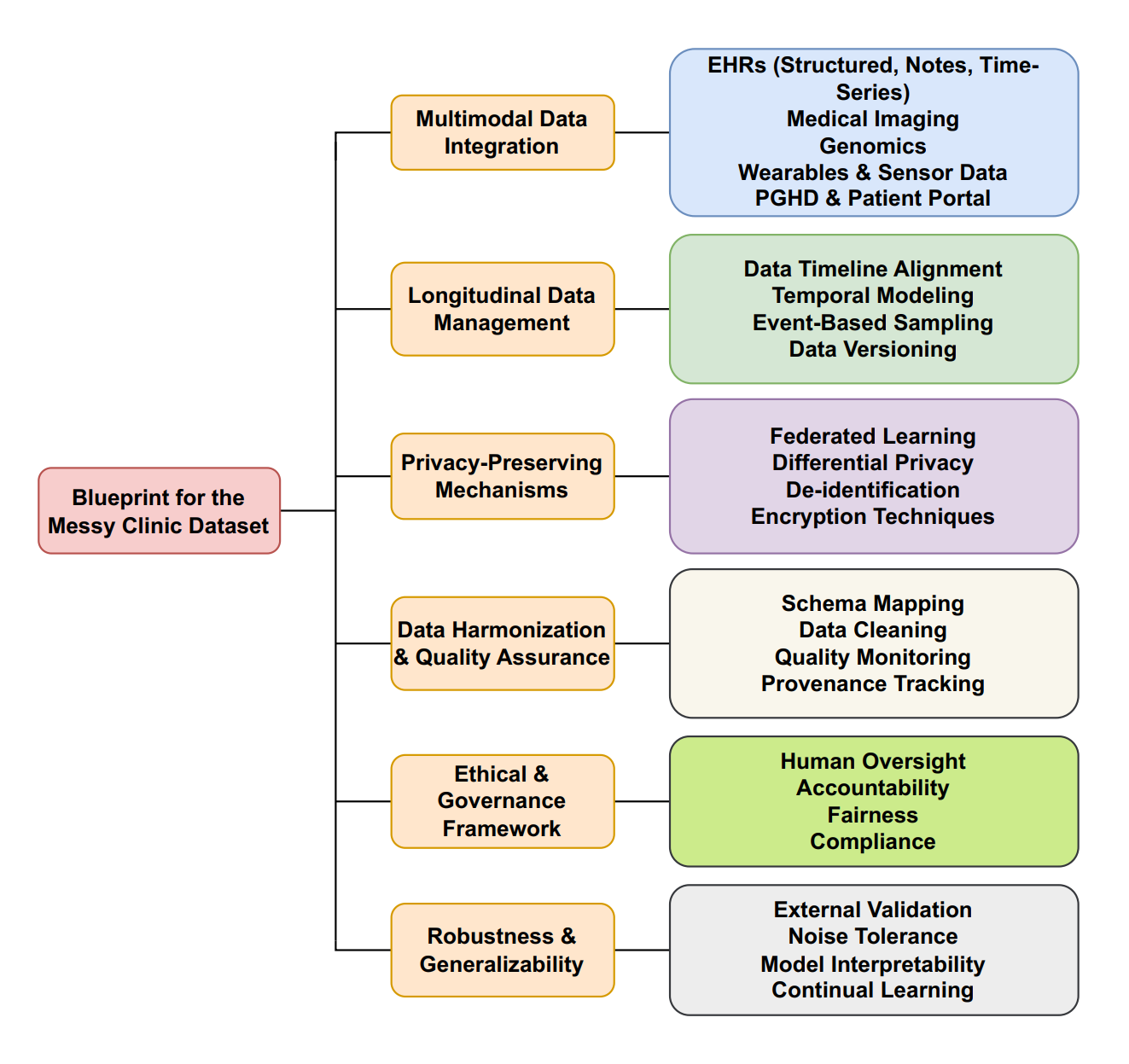
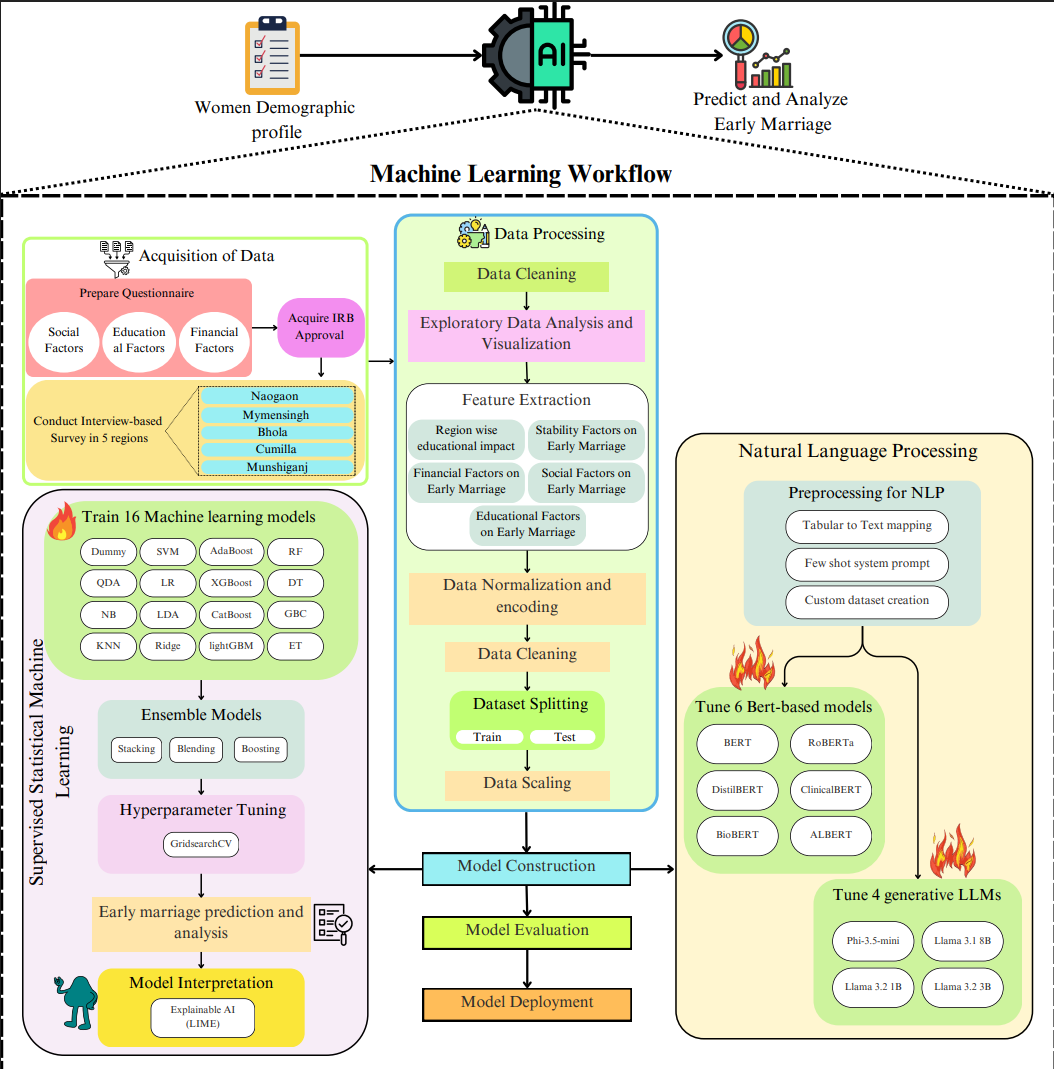 PANCHINI: Predictive Analytics for Child Marriage in Bangladesh Using Machine Learning Insights2025Under review at the Array journal
PANCHINI: Predictive Analytics for Child Marriage in Bangladesh Using Machine Learning Insights2025Under review at the Array journal